Efficient Deep CNN-BiLSTM Model for Network Intrusion Detection
Abstract
Since the widespread adoption of cloud technologies, there has been an increase in the demand for Network Intrusion Detection Systems. With ever-increasing network traffic, Network Intrusion Detection (NIDS) is a critical component of network security, and a highly efficient NIDS is required, given the frequency with which new types of attacks emerge. These intrusion detection systems are based on either a pattern matching system, or an anomaly detection system based on AI/ML. Pattern matching methods typically have high False Positive Rates, whereas AI/ML-based methods rely on finding a metric/feature or a correlation between a set of metrics/features to predict the possibility of an attack. The most common of these are KNN, SVM, and others, which operate on a limited set of features, have lower accuracy, and suffer from higher False Positive Rates. This paper proposed a deep learning model that incorporates learning of spatial and temporal data features by combining the distinct strengths of a Convolutional Neural Network and a Bi-directional LSTM. The publicly available dataset NSL-KDD is used to train and test the model in this paper. The proposed model has a high detection rate and a low False Positive Rate. The proposed model outperforms many cutting-edge Network Intrusion Detection systems that use Machine Learning/Deep Learning models.
Data Preprocessing
The proposed model in this paper is tested using the NSL-KDD dataset. The University of New Brunswick made the NSL-KDD dataset available. Normalization of numeric features and One Hot Encoding of Categorical features in the dataset are commonly used for preprocessing datasets. There are categorical features in the NSL-KDD dataset that should be converted to numerical values for our deep learning model to produce accurate predictions. As a result, in the pre-processing section, these columns were converted into numerical values using the pandas python library’s get-dummies function. One-hot encoding is preferred over label encoding because label encoding produces multiple numbers in the same column, which the model may misinterpret as being in a specific order, affecting classification. Normalization is the process of rescaling data into a specific range in order to reduce redundancy and improve model training time. The paper employs Min-Max Normalization, which rescales the data range to [0,1].
Stratification is the process of rearranging data so that each fold is an accurate representation of the whole. The stratified K-cross fold validation technique divides the dataset into K sets, and the model trains on K-1 folds before being validated on the Kth fold. This is repeated until all of the folds have been used to validate the model. Stratification ensures that each fold is a good representation of the entire dataset, which leads to parameter finetuning and improves the model’s ability to classify attacks. The K-cross fold method is preferred over other validation methods because it performs better and requires less computation power.
Data Analysis and Visualization
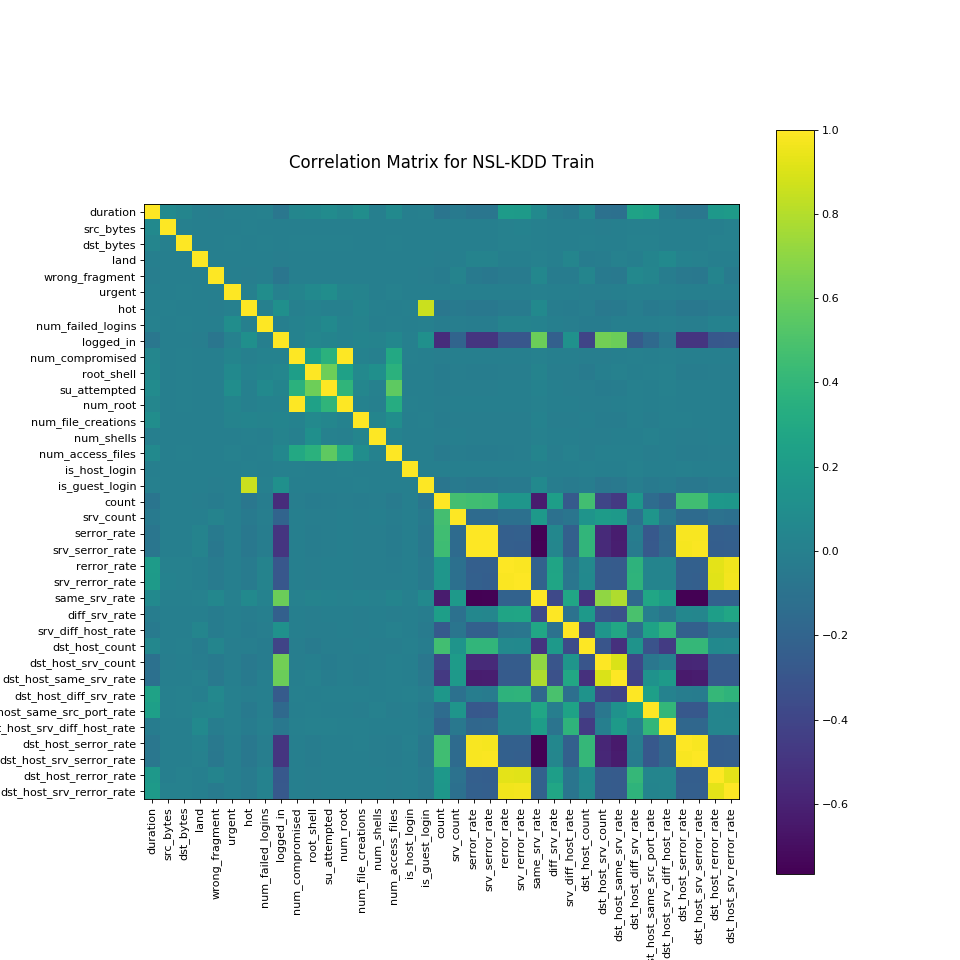
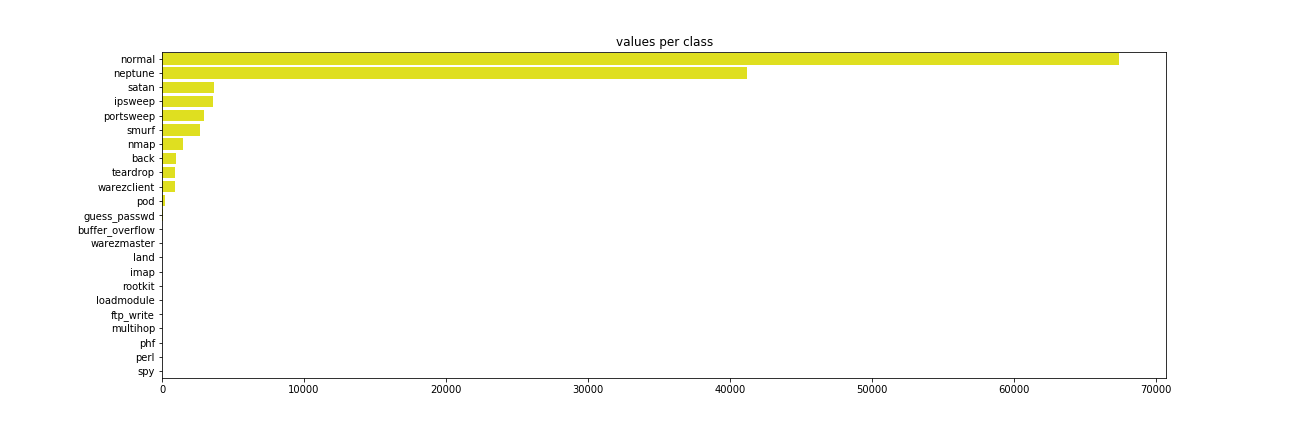
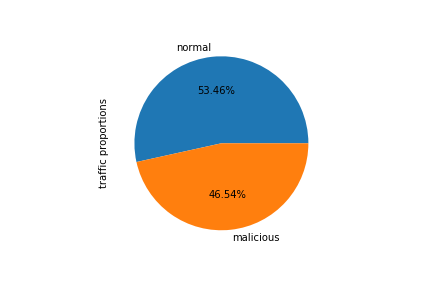
Correlation matrix was created to summarize large amount of data to see the patterns. In the NSL-KDD Dataset, most of the variables doesn’t correlate with each other. As evident, very few variables negatively correlate with each other. Figure 3 shows the different types of attacks and the counts of each category of attacks. ‘Normal’ refers to no attack and rest all classes refer to the type of attack. 53.46% of all data points are normal which means those are not attacks and the rest 46.54% are attacks.
Pie Charts between attack and protocol, attack and flag, attack and service were created to visualize interaction between them. Clear trend was observed between the protocols and type of attacks. In network traffic analysis, protocol is a simple tool to create some initial buckets to categorize our data. That helps us see that most attacks are going to target a specific protocol. There are several (satan, nmap, ipsweep) that are cross-protocol attacks. And also, icmp data is less frequently found in normal traffic.
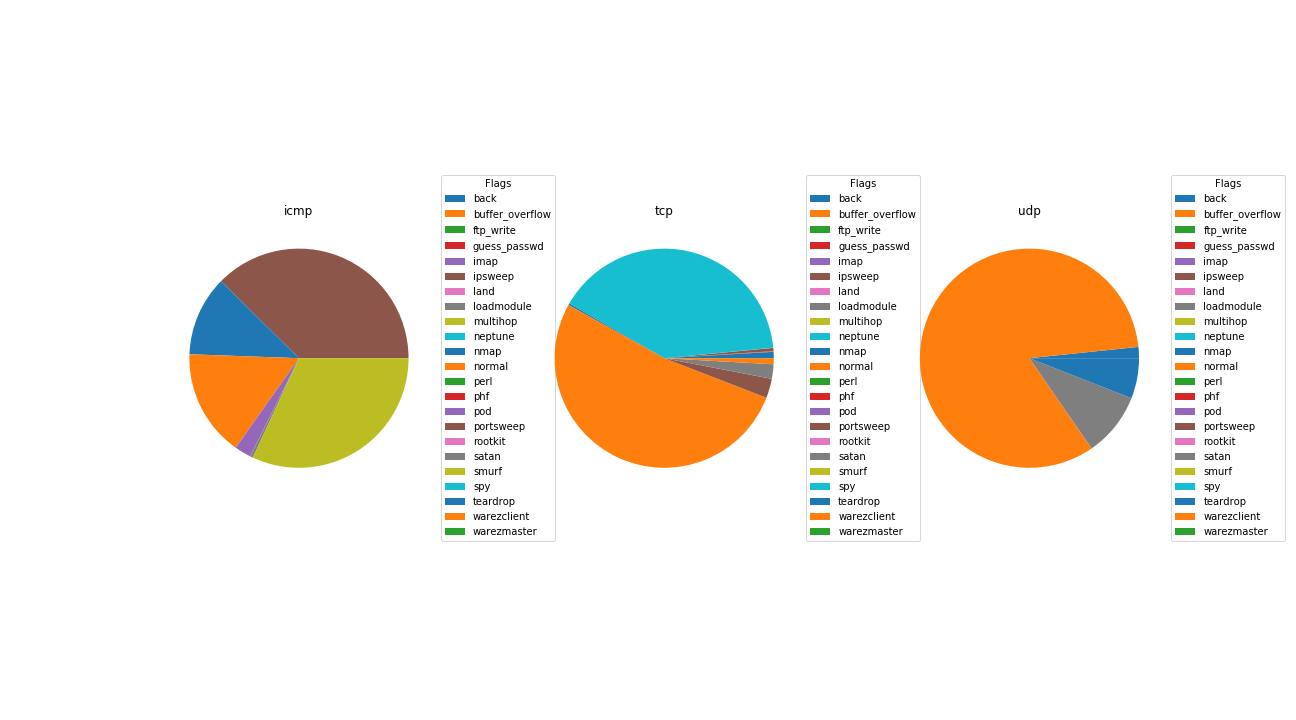
The thing to notice here is the difference in each protocol type. Initial impression is that protocol may be useful in being able to identify the type of traffic being observed. Let’s see if flag and service behave the same way.
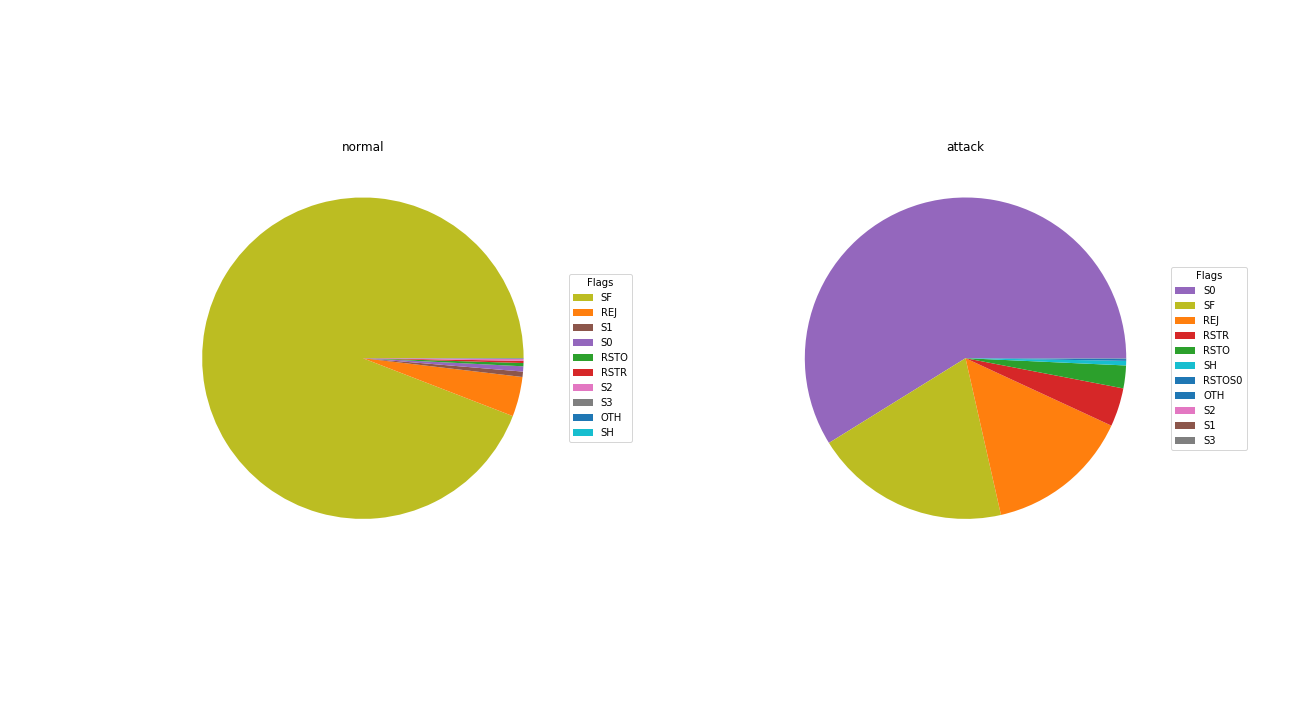
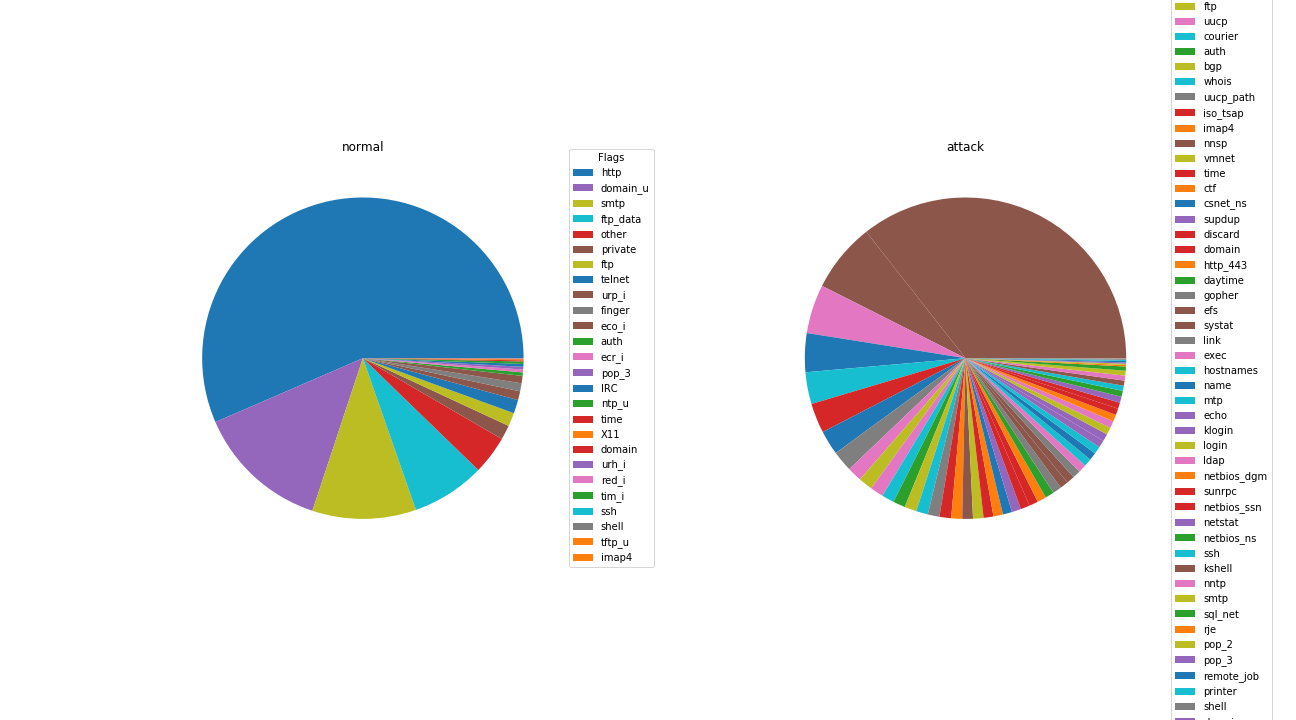
There are a lot of services in the attack set. A huge amount of normal traffic is http whereas attack traffic is all over the place. That is interesting as it means that attacks are searching for many different paths into systems some well-travelled and some not. If this is observed from the eyes of a network administrator, the combination of protocol, flag and service seem like they should tell a lot about the nature of our traffic.
Key Findings
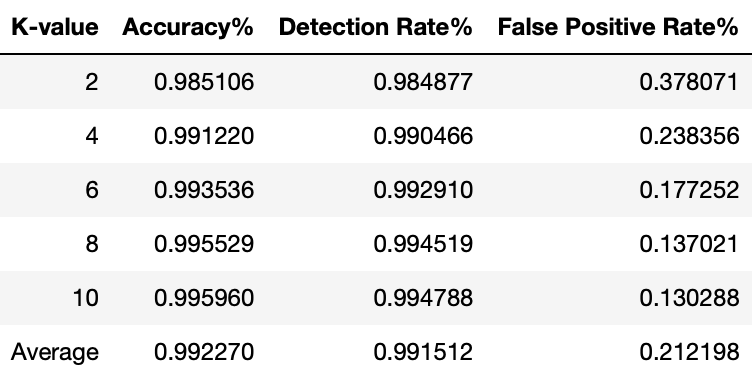
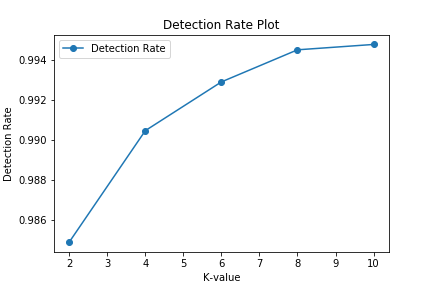
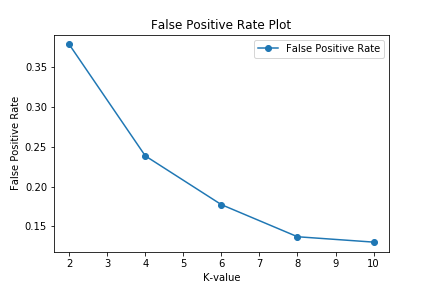
The proposed model provides an average accuracy of 99.22% for the NSL-KDD dataset in multiclass, with the best accuracy of 99.59% for k-value=10. The average Detection Rate is 99.15%, with k-value = 10 yielding the best result of 99.47%. The average FPR percent is 0.0021, with k-value=10 yielding the best value of 0.0013. Model performance for different k-values can be observed in above figure. The proposed model has a high detection rate (DR %) and a low false positive rate (FPR %), which are plotted in below figures for various k-values. The maximum accuracy is 99.59% and the detection rate is 99.47% when k is 10 and correctly so because as the number of folds increases, more samples of each attack/normal class are available for the model to train and thus the model can classify them better.
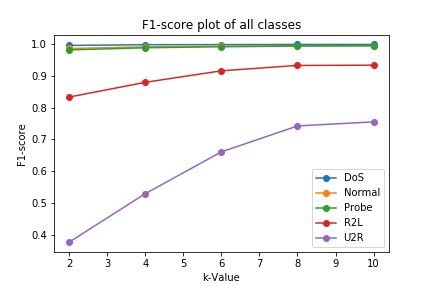
F1-score of each of the 5 classes is plotted in below figure. The model is able to classify Normal, DoS, Probe very accurately. The model has good capability to detect R2L class. F1-score is very less for U2R attack class compared to other classes. This is acceptable since there are very less data points for that class compared to other classes.
Below figure depicts the confusion matrix of the best model which is when k = 10. The proposed model was able to classify Normal, DoS, Probe very accurately. U2R class has very less data points compared to others. It has a total of 119 observations which is less than 0.1% of the dataset, out of which 108 were used for used for training and rest 11 were used for testing. This can be observed in the plotted confusion matrix.

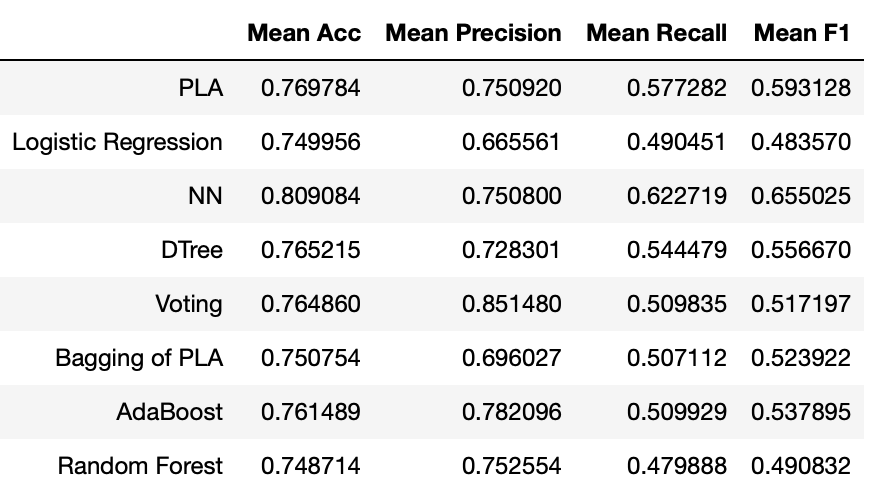
Comparing the proposed model to others such as Logistic Regression, Decision Tree, Random Forest, AdaBoost, and so on. In comparison, it is clear that the proposed model provides significantly better performance across all metrics, including Accuracy, Detection Rate, and False Positive Rate. As a result, the proposed model is more suitable for use in Intrusion Detection Systems. The comparison is given in below figure.
Recommendations
There are several ways to improve upon the findings of this project. One way to elaborate on the project’s goal would be to include additional data points. And also, Random Oversampling can be used to overcome the problem of imbalanced data. Random oversampling duplicates data points from the minority class at random, reducing data imbalance and improving minority class prediction accuracy. Another recommendation would be to be research on several pre-trained Deep Learning models to find the most accurate model possible. This would make a good candidate for extended deep learning analysis.
Conclusion
This paper proposes a model for analyzing network traffic that takes into account a wide range of variables such as protocol type, service type, and so on. The use of CNN and Bi-directional LSTM layers allowed for the learning of spatial and temporal features. After training and testing on the NSL-KDD dataset, the proposed model yields promising prospective real-time usage for Intrusion Detection systems. Although the model would almost certainly need to be professionally monitored in a production environment, the risk of overfitting, misclassification, or error rate creep is significantly lower than that of many other machine learning models currently available. Furthermore, it necessitates fewer computing resources, less training time, and less specialized care during implementation and maintenance. Finally, the predictive responses are simple to understand and can be applied to a wide range of categories. As a result of the findings, the need to optimize the model for the U2R and Worms categories of attacks will be investigated in the future to allow testing in a honeypot system.